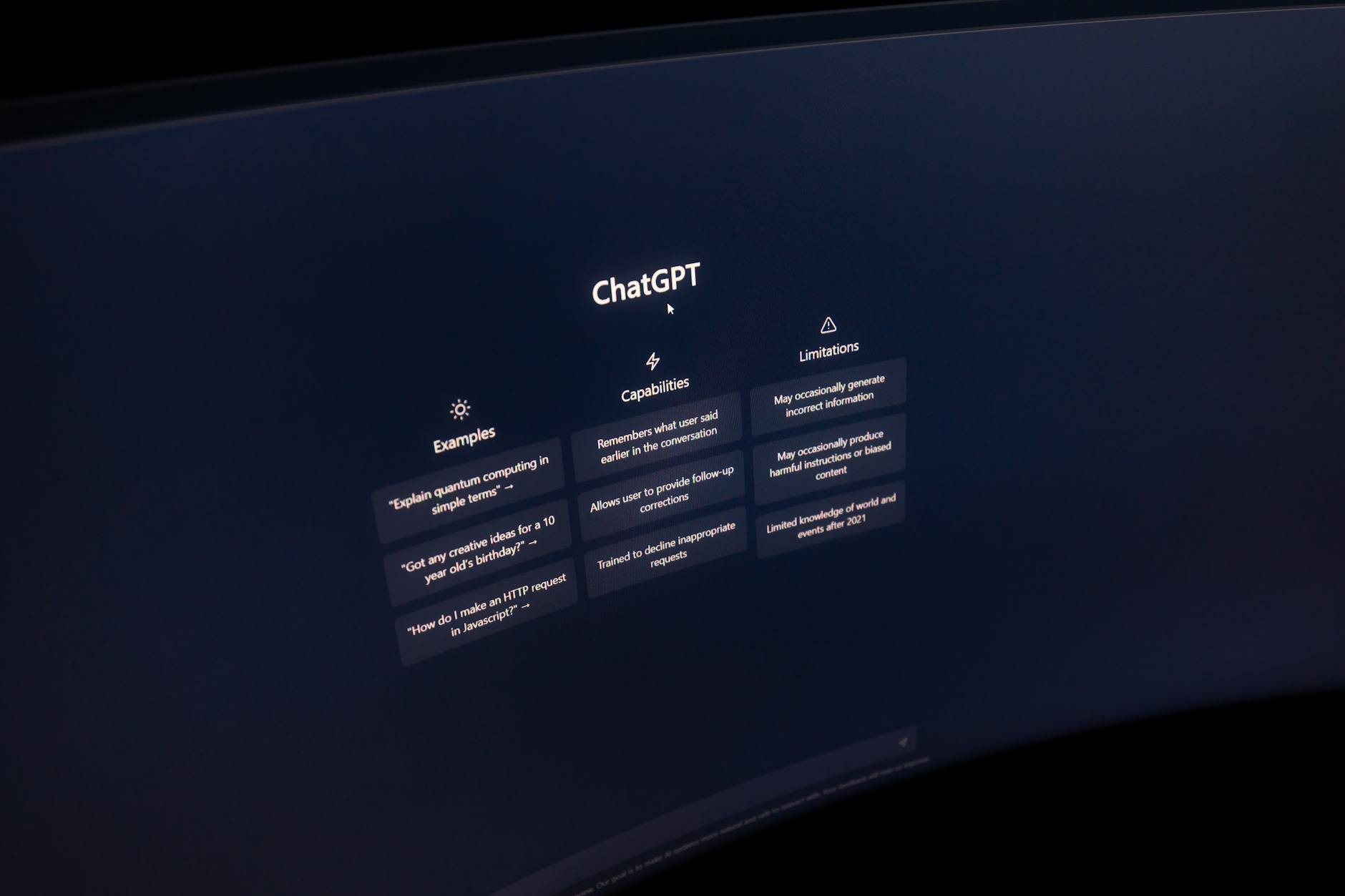
Understanding MCPs: Your AI Agent's Supercharger (What they are, why they matter for intelligence, common misconceptions, and how they compare to traditional setups)
At the heart of genuinely intelligent AI agents lie Modular Cognitive Processes (MCPs). Unlike monolithic AI models that attempt to encompass all capabilities within a single, complex architecture, MCPs break down an agent's intelligence into discrete, specialized modules. Think of them as individual brain regions, each optimized for a specific cognitive task – perhaps one for natural language understanding, another for predictive modeling, and a third for complex problem-solving. This modularity isn't just about organizational neatness; it's a fundamental shift in how AI learns, adapts, and performs. By allowing these specialized modules to operate semi-independently yet communicate seamlessly, MCPs enable more robust, explainable, and ultimately, more intelligent AI behaviors. They are the supercharger because they allow for targeted improvements and easier integration of new capabilities without destabilizing the entire system.
The significance of MCPs for enhancing AI intelligence cannot be overstated. They address several critical limitations of traditional, 'end-to-end' AI setups. For one, MCPs foster greater interpretability; when an AI makes a decision, it's often possible to trace which specific module or modules were primarily responsible, moving us closer to explainable AI. Furthermore, they allow for incremental learning and adaptation. If a new domain or skill needs to be integrated, a new module can be developed and added, or an existing one refined, without retraining the entire agent from scratch. Common misconceptions often equate MCPs with mere microservices, but they are fundamentally different because MCPs focus on cognitive separation and interaction to achieve intelligence, not just task distribution. They compare to traditional setups much like a specialized team of experts compares to a single generalist trying to do everything – the former is inherently more capable and adaptable.
For those seeking a robust scrapingbee alternative, several powerful options offer enhanced features and competitive pricing. Many developers appreciate the flexibility and extensive documentation provided by these alternatives, making them suitable for a wide range of web scraping projects. Whether you prioritize speed, anti-bot capabilities, or cost-effectiveness, exploring different providers will help you find the perfect fit for your specific needs.
Deploying AI Agents on MCPs: A Practical Guide to Scalable Intelligence (Step-by-step setup, optimizing for performance, troubleshooting common issues, and future-proofing your AI infrastructure)
Deploying AI agents on Multi-Cloud Platforms (MCPs) offers unparalleled scalability and resilience, but requires a strategic, step-by-step approach. Begin with a meticulous platform selection and configuration, considering factors like vendor lock-in, data sovereignty, and specialized AI/ML services (e.g., GCP's AI Platform, AWS SageMaker). Next, containerize your AI agents using Docker or Podman, ensuring all dependencies are bundled. Orchestration tools like Kubernetes (EKS, AKS, GKE) are paramount for managing containerized workloads across different cloud providers, enabling automated scaling and self-healing. Implement a robust CI/CD pipeline, leveraging tools like Jenkins or GitLab CI/CD, to automate the build, test, and deployment of your AI agents. This automation is crucial for rapid iteration and ensuring consistent deployments across your heterogeneous MCP environment. Finally, establish comprehensive monitoring and logging solutions (e.g., Prometheus, Grafana, ELK stack) to gain real-time insights into agent performance and resource utilization.
Optimizing for performance and troubleshooting common issues are critical for maintaining scalable intelligence on MCPs. To achieve peak performance, employ resource governance strategies, such as setting appropriate CPU/memory limits and requests for your Kubernetes pods, and leveraging autoscaling groups to dynamically adjust resources based on demand. Implement intelligent load balancing across cloud providers to distribute traffic efficiently and mitigate single points of failure. When troubleshooting, common issues often stem from network latency between clouds, misconfigured IAM roles/permissions, or data consistency challenges. Utilize distributed tracing tools to pinpoint bottlenecks and analyze logs across your MCP for a holistic view. Future-proofing your AI infrastructure involves adopting cloud-agnostic architectures, prioritizing open standards, and regularly evaluating emerging technologies like serverless functions for event-driven AI. Furthermore, investing in robust data governance and security frameworks across all your cloud providers is paramount to protect sensitive AI models and their training data, ensuring long-term operational integrity.